In computer science and information theory, Huffman coding is an entropy encoding algorithm used for lossless data compression. The term refers to the use of a variable-length code table for encoding a source symbol (such as a character in a file) where the variable-length code table has been derived in a particular way based on the estimated probability of occurrence for each possible value of the source symbol. It was developed by David A. Huffman while he was a Ph.D. student at MIT, and published in the 1952 paper "A Method for the Construction of Minimum-Redundancy Codes." Huffman became a member of the MIT faculty upon graduation and was later the founding member of the Computer Science Department at the University of California, Santa Cruz, now a part of the Baskin School of Engineering.
Huffman coding uses a specific method for choosing the representation for each symbol, resulting in a prefix-free code (sometimes called "prefix codes") (that is, the bit string representing some particular symbol is never a prefix of the bit string representing any other symbol) that expresses the most common characters using shorter strings of bits than are used for less common source symbols. Huffman was able to design the most efficient compression method of this type: no other mapping of individual source symbols to unique strings of bits will produce a smaller average output size when the actual symbol frequencies agree with those used to create the code. A method was later found to do this in linear time if input probabilities (also known as weights) are sorted.
For a set of symbols with a uniform probability distribution and a number of members which is a power of two, Huffman coding is equivalent to simple binary block encoding, e.g., ASCII coding. Huffman coding is such a widespread method for creating prefix-free codes that the term "Huffman code" is widely used as a synonym for "prefix-free code" even when such a code is not produced by Huffman's algorithm.
Although Huffman coding is optimal for a symbol-by-symbol coding with a known input probability distribution, its optimality can sometimes accidentally be over-stated. For example, arithmetic coding and LZW coding often have better compression capability. Both these methods can combine an arbitrary number of symbols for more efficient coding, and generally adapt to the actual input statistics, the latter of which is useful when input probabilities are not precisely known.
History
Problem definition
Given. A set of symbols and their weights (usually probabilities). Find. A prefix-free binary code (a set of codewords) with minimum expected codeword length (equivalently, a tree with minimum weighted path length).
Formalized description
For any code that is biunique, meaning that the code is uniquely decodeable, the sum of the probability budgets across all symbols is always less than or equal to one. In this example, the sum is strictly equal to one; as a result, the code is termed a complete code. If this is not the case, you can always derive an equivalent code by adding extra symbols (with associated null probabilities), to make the code complete while keeping it biunique.
As defined by Shannon (1948), the information content h (in bits) of each symbol ai with non-null probability is

The information content of symbols with null probability is not defined, but in practice can be defined as any finite value because this information will be absent from the encoded message (unless the message A has an infinite symbol length, but in this case these symbols have an infinitesimal positive probability 0).
The entropy H (in bits) is the weighted sum, across all symbols ai with non-zero probability wi, of the information content of each symbol:
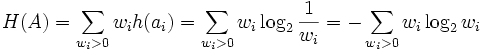
All symbols with zero probability have in theory a positive infinite entropy, but as they are necessarily absent from the original message to be encoded, they don't contribute to the entropy of the encoded message (unless the message is infinite) ; so they could be made equivalent to a zero entropy within the sum above, removing the restriction on the suitable indices.
As a consequence of Shannon's Source coding theorem, the entropy is a measure of the smallest codeword length that is theoretically possible for the given alphabet with associated weights. In this example, the weighted average codeword length is 2.25 bits per symbol, only slightly larger than the calculated entropy of 2.205 bits per symbol. So not only is this code optimal in the sense that no other feasible code performs better, but it is very close to the theoretical limit established by Shannon.
Note that, in general, a Huffman code need not be unique, but it is always one of the codes minimizing L(C).
Samples
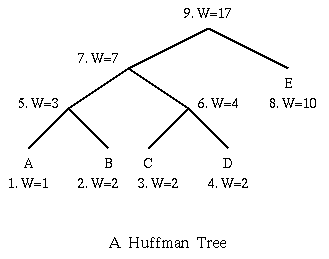
The technique works by creating a binary tree of nodes. These can be stored in a regular array, the size of which depends on the number of symbols(N). A node can be either a leaf node or an internal node. Initially, all nodes are leaf nodes, which contain the symbol itself, the weight (frequency of appearance) of the symbol and optionally, a link to a parent node which makes it easy to read the code (in reverse) starting from a leaf node. Internal nodes contain symbol weight, links to two child nodes and the optional link to a parent node. As a common convention, bit '0' represents following the left child and bit '1' represents following the right child. A finished tree has N leaf nodes and N−1 internal nodes.
A linear-time* method to create a Huffman tree is to use two queues, the first one containing the initial weights (along with pointers to the associated leaves), and combined weights (along with pointers to the trees) being put in the back of the second queue. This assures that the lowest weight is always kept at the front of one of the two queues.
Creating the tree:
It is generally beneficial to minimize the variance of codeword length. For example, a communication buffer receiving Huffman-encoded data may need to be larger to deal with especially long symbols if the tree is especially unbalanced. To minimize variance, simply break ties between queues by choosing the item in the first queue. This modification will retain the mathematical optimality of the Huffman coding while both minimizing variance and minimizing the length of the longest character code.
* This method is linear time assuming that you already have the leaf nodes sorted by initial weight. If not, sorting them will take O(nlogn) time.
Start with as many leaves as there are symbols.
Enqueue all leaf nodes into the first queue (by probability in increasing order so that the least likely item is in the head of the queue).
While there is more than one node in the queues:
- Dequeue the two nodes with the lowest weight.
Create a new internal node, with the two just-removed nodes as children (either node can be either child) and the sum of their weights as the new weight.
Enqueue the new node into the rear of the second queue.
The remaining node is the root node; the tree has now been generated. Basic technique
The frequencies used can be generic ones for the application domain that are based on average experience, or they can be the actual frequencies found in the text being compressed. (This variation requires that a frequency table or other hint as to the encoding must be stored with the compressed text; implementations employ various tricks to store tables efficiently.)
Huffman coding is optimal when the probability of each input symbol is a negative power of two. Prefix-free codes tend to have slight inefficiency on small alphabets, where probabilities often fall between these optimal points. "Blocking", or expanding the alphabet size by coalescing multiple symbols into "words" of fixed or variable-length before Huffman coding, usually helps, especially when adjacent symbols are correlated (as in the case of natural language text). The worst case for Huffman coding can happen when the probability of a symbol exceeds 2 = 0.5, making the upper limit of inefficiency unbounded. These situations often respond well to a form of blocking called run-length encoding.
Arithmetic coding produces slight gains over Huffman coding, but in practice these gains have seldom been large enough to offset arithmetic coding's higher computational complexity and patent royalties. (As of July 2006, IBM owns patents on many methods of arithmetic coding in several jurisdictions; see US patents on arithmetic coding.)
Main properties
Many variations of Huffman coding exist, some of which use a Huffman-like algorithm, and others of which find optimal prefix codes (while, for example, putting different restrictions on the output). Note that, in the latter case, the method need not be Huffman-like, and, indeed, need not even be polynomial time. An exhaustive list of papers on Huffman coding on its variations is given by "Code and Parse Trees for Lossless Source Encoding"[1].
Variations
The n-ary Huffman algorithm uses the {0, 1, ..., n − 1} alphabet to encode message and build an n-ary tree. This approach was considered by Huffman in his original paper.
n-ary Huffman coding
A variation called adaptive Huffman coding calculates the frequencies dynamically based on recent actual frequencies in the source string. This is somewhat related to the LZ family of algorithms.
Adaptive Huffman coding
Most often, the weights used in implementations of Huffman coding represent numeric probabilities, but the algorithm given above does not require this; it requires only a way to order weights and to add them. The Huffman template algorithm enables one to use any kind of weights (costs, frequencies, pairs of weights, non-numerical weights) and one of many combining methods (not just addition). Such algorithms can solve other minimization problems, such as minimizing [2].
[2].
Huffman template algorithm
Length-limited Huffman coding is a variant where the goal is still to achieve a minimum weighted path length, but there is an additional restriction that the length of each codeword must be less than a given constant. The package-merge algorithm solves this problem with a simple greedy approach very similar to that used by Huffman's algorithm. Its time complexity is O(nL), where L is the maximum length of a codeword. No algorithm is known to solve this problem with the same efficiency as conventional Huffman coding,
Length-limited Huffman coding
In the standard Huffman coding problem, it is assumed that each symbol in the set that the code words are constructed from has an equal cost to transmit: a code word whose length is N digits will always have a cost of N, no matter how many of those digits are 0s, how many are 1s, etc. When working under this assumption, minimizing the total cost of the message and minimizing the total number of digits are the same thing.
Huffman coding with unequal letter costs is the generalization in which this assumption is no longer assumed true: the letters of the encoding alphabet may have non-uniform lengths, due to characteristics of the transmission medium. An example is the encoding alphabet of Morse code, where a 'dash' takes longer to send than a 'dot', and therefore the cost of a dash in transmission time is higher. The goal is still to minimize the weighted average codeword length, but it is no longer sufficient just to minimize the number of symbols used by the message. No algorithm is known to solve this in the same manner or with the same efficiency as conventional Huffman coding.
Huffman coding with unequal letter costs
In the standard Huffman coding problem, it is assumed that any codeword can correspond to any input symbol. In the alphabetic version, the alphabetic order of inputs and outputs must be identical. Thus, for example, could not be assigned code
could not be assigned code 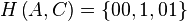 , but instead should be assigned either
, but instead should be assigned either 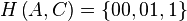 or
or  . This is also known as the Hu-Tucker problem, after the authors of the paper presenting the first linearithmic solution to this optimal binary alphabetic problem, which has some similarities to Huffman algorithm, but is not a variation of this algorithm. These optimal alphabetic binary trees are often used as binary search trees. If weights corresponding to the alphabetically ordered inputs are in numerical order, the Huffman code has the same lengths as the optimal alphabetic code, which can be found from calculating these lengths. The resulting alphabetic code is sometimes called the canonical Huffman code and is often the code used in practice, due to ease of encoding/decoding. The technique for finding this code is sometimes called Huffman-Shannon-Fano coding, since it is optimal like Huffman coding, but alphabetic in weight probability, like Shannon-Fano coding. The Huffman-Shannon-Fano code corresponding to the example is {000,001,01,10,11}, which, having the same codeword lengths as the original solution, is also optimal.
. This is also known as the Hu-Tucker problem, after the authors of the paper presenting the first linearithmic solution to this optimal binary alphabetic problem, which has some similarities to Huffman algorithm, but is not a variation of this algorithm. These optimal alphabetic binary trees are often used as binary search trees. If weights corresponding to the alphabetically ordered inputs are in numerical order, the Huffman code has the same lengths as the optimal alphabetic code, which can be found from calculating these lengths. The resulting alphabetic code is sometimes called the canonical Huffman code and is often the code used in practice, due to ease of encoding/decoding. The technique for finding this code is sometimes called Huffman-Shannon-Fano coding, since it is optimal like Huffman coding, but alphabetic in weight probability, like Shannon-Fano coding. The Huffman-Shannon-Fano code corresponding to the example is {000,001,01,10,11}, which, having the same codeword lengths as the original solution, is also optimal.
 Applications
Applications
Modified Huffman coding - used in fax machines
Shannon-Fano coding
Data compression
No comments:
Post a Comment